본 포스팅은 다양한 레퍼런스 기준으로 작성되었습니다.
우리는 저지연 데이터 스트리밍 애플리케이션에 의해 주도되는 실시간 데이터와 통찰력의 시대에 살고 있습니다. 오늘날 모든 사람은 모든 애플리케이션에서 개인화된 경험을 기대하며, 조직은 비즈니스 운영 및 의사 결정 속도를 높이기 위해 끊임없이 혁신하고 있습니다. 생성되는 시간에 민감한 데이터의 양이 빠르게 증가하고 있으며, 새로운 비즈니스와 고객 사용 사례에 다양한 형식의 데이터가 도입되고 있습니다. 따라서 조직이 실시간 비즈니스 애플리케이션과 더 나은 고객 경험을 제공하기 위해 저지연, 확장 가능하고 안정적인 데이터 스트리밍 인프라를 도입하는 것이 중요합니다. [1]
Amazon Kinesis Data Streams는 클라우드 네이티브, 서버리스 스트리밍 데이터 서비스로, 모든 규모에서 실시간 데이터를 쉽게 캡처, 처리 및 저장할 수 있습니다. Kinesis Data Streams를 사용하면 수십만 개의 소스에서 초당 수백 기가바이트의 데이터를 수집하고 처리하여 실시간으로 정보를 처리하는 애플리케이션을 쉽게 작성할 수 있습니다. 수집된 데이터는 밀리초 단위로 제공되어 실시간 대시보드, 실시간 이상 감지, 동적 가격 책정과 같은 실시간 분석 사용 사례에 사용할 수 있습니다. 기본적으로 Kinesis Data Stream 내의 데이터는 24시간 동안 저장되며 데이터 보존 기간을 365일로 늘릴 수 있는 옵션이 있습니다. 고객이 여러 애플리케이션에서 동일한 데이터를 실시간으로 처리하려는 경우 Enhanced Fan-Out(EFO) 기능을 사용할 수 있습니다. 이 기능이 출시되기 전에는 스트림에서 데이터를 사용하는 모든 애플리케이션이 2MB/초/샤드 출력을 공유했습니다. 향상된 팬아웃을 사용하도록 스트림 소비자를 구성함으로써 각 데이터 소비자는 샤드당 전용 2MB/초 파이프의 읽기 처리량을 받아 데이터 검색 지연 시간을 더욱 줄일 수 있습니다. [1]ㅅ
시계열 데이터의 실시간 분석
시계열 데이터는 시간 간격에 따라 기록된 일련의 데이터 포인트로, 시간에 따라 변화하는 이벤트를 측정하기 위한 것입니다. 예를 들어 시간에 따른 주가, 웹페이지 클릭 스트림, 시간에 따른 기기 로그가 있습니다. 고객은 시계열 데이터를 사용하여 시간에 따른 변화를 모니터링하여 이상을 감지하고 패턴을 식별하며 특정 변수가 시간에 따라 어떻게 영향을 받는지 분석할 수 있습니다. 시계열 데이터는 일반적으로 여러 소스에서 대량으로 생성되며 거의 실시간으로 비용 효율적으로 수집해야 합니다.
일반적으로 고객이 시계열 데이터를 처리할 때 달성하고자 하는 주요 목표는 세 가지입니다.
- 시스템 성능에 대한 실시간 통찰력을 얻고 이상을 감지합니다.
- 최종 사용자 행동을 이해하여 추세를 추적하고 이러한 통찰력을 바탕으로 시각화를 쿼리/구축합니다.
- 보관 데이터와 자주 액세스하는 데이터를 모두 수집하고 저장할 수 있는 내구성 있는 저장 솔루션을 갖추세요.
Kinesis Data Streams를 사용하면 고객은 수천 개의 소스에서 테라바이트 규모의 시계열 데이터를 지속적으로 수집하여 정리, 보강, 저장, 분석 및 시각화할 수 있습니다.
다음 아키텍처 패턴은 Kinesis Data Streams를 사용하여 시계열 데이터에 대한 실시간 분석을 달성하는 방법을 보여줍니다.
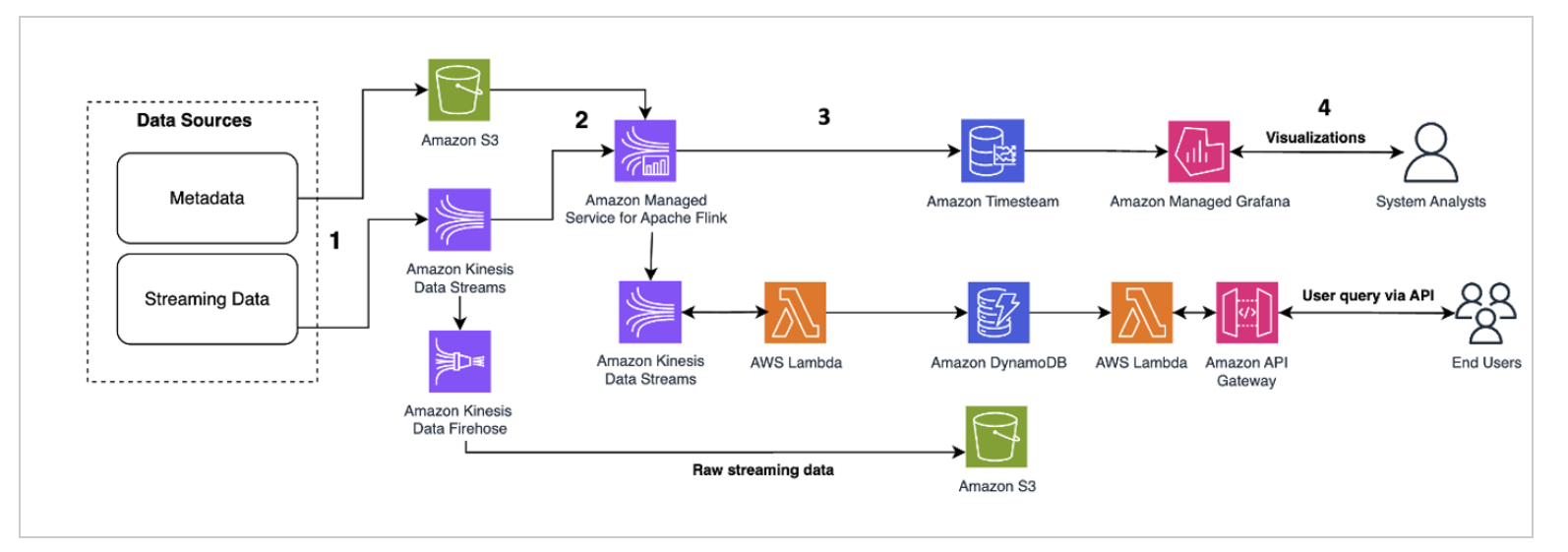
대용량 데이터의 실시간 수집
AWS IoT FleetWise를 활용하면 실시간 처리 혹은 배치 처리에 따라 저장소의 선택도 자유롭기 때문에, 성격이 다른 콘텐츠 개발도 손쉽게 처리할 수 있었고, 또한 AWS IoT FleetWise vision system을 이용했을 때 비정형 영상 데이터의 수집도 동시에 처리할 수 있었습니다. 특히 실시간 추론을 위해서, AWS IoT FleetWise의 목표 저장소를 Amazon Timestream 시계열 데이터베이스로 선택한다면 10초 이내에 추론을 시작할 수 있습니다. [2]
AWS IoT FleetWise의 에지 에이전트(Edge Agent)를 생성하여 차량과 클라우드 사이의 통신을 안정적으로 수행할 수 있습니다. 에지 에이전트를 활용하면 캠페인의 생성부터 설치까지 모든 프로세스 단계를 제어할 수 있습니다. 바로 이 캠페인에 대한 RSP의 학습데이터 수집을 예로 들면 아래와 같은 특징을 꼽을 수 있습니다.
- 트리거를 이용한 시그널 비교 : 시그널 간의 비교를 상수 값이 아닌 시그널과 시그널간 비교로 원하는 데이터만 선별 수집
- 원하는 주기마다 수집 : 2초에 한 번씩 데이터를 수집하게끔 minimumTriggerIntervalMs설정
- 카메라 영상 수집 : signalsToCollect에 Signal Catalog에서 정의된 이름을 사용 [2]
실시간으로 추론을 진행해야 하기 때문에 데이터가 적재됨과 동시에 학습할 수 있는 Amazon Timestream 시계열 데이터베이스를 사용합니다. Amazon Timestream에 적재된 시그널 데이터를 Amazon Lambda에서 쿼리하여 추론을 수행하고, 수행된 결과는 Amazon RDS(Relational Database Service)에 적재됩니다. 적재된 데이터의 분석 결과는 Amazon S3 정적 Web Hosting 기능을 활용하여 운전자에게 즉시 결과 값을 보여줍니다. 데이터 수집, 추론, 결과 확인까지 50초 이내에 진행이 되어 운전자는 주행을 마치거나 주행 중에 결과를 확인할 수 있습니다. Amazon Timestream 데이터베이스에서 쿼리를 사용할 때 WHERE를 사용한 조건문의 경우 데이터베이스의 크기에 따라 응답속도의 지연 문제가 발생할 수 있습니다.
Amazon Timestream 데이터베이스의 내부 정렬도 시간 순서로 되어 있기 때문에 time between을 이용한 구절과 동일한 결과를 얻을 수 있었습니다. 또한 쿼리의 응답 속도도 기존 5분에서 30초로 줄일 수 있었습니다. 이렇게 수집된 데이터는 아래와 같은 일련의 과정을 통해 사용자에게 표시됩니다.
- AWS Lambda를 통한 추론
- 추론된 결과를 Amazon RDS에 적재
- HL Mando에서 자체 제작한 대시보드(Mando Cloud Service Platform)에 출력

실시간 데이터 처리를 위해서 어떤 아키텍쳐를 사용해야 할까 이론적으로 공부를 하면서 위와 같은 핵심적인 내용을 알 수 있었다.
AWS IoT Fleetwise를 사용하는 경우, Target Database를 Amazon Timestream으로 함으로써 빠른 추론 결과를 얻을 수 있음
[1] AWS 빅데이터 블로그: Amazon Kinesis Data Streams를 사용한 실시간 분석을 위한 아키텍처 패턴, 1부
Architectural patterns for real-time analytics using Amazon Kinesis Data Streams, part 1 | Amazon Web Services
We’re living in the age of real-time data and insights, driven by low-latency data streaming applications. Today, everyone expects a personalized experience in any application, and organizations are constantly innovating to increase their speed of busine
aws.amazon.com
[2] AWS 빅데이터 블로그: AWS IoT FleetWise를 활용한 HL Mando의 실시간 차량 데이터 플랫폼 구축 사례
AWS IoT FleetWise를 활용한 HL Mando의 실시간 차량 데이터 플랫폼 구축 사례 | Amazon Web Services
HL Mando는 ‘세상을 더 안전하고, 친환경적이며, 편리하게 모든 고객이 자유로워지는 내일’의 역사를 만들어 나가는 글로벌 자동차 부품 전문 기업입니다. 조향장치(Steering), 제동장치(Brake), 현
aws.amazon.com
[3] 높은 처리량과 낮은 대기 시간을 위해 Kinesis Data Streams 확장
https://www.youtube.com/watch?v=oAliBHw_08M
'Data Engineering > AWS' 카테고리의 다른 글
| AWS ECS에 대한 이해 (0) | 2024.05.16 |
|---|
